
Platforma VMware jest dziś przede wszystkim narzędziem do porządkowania środowisk aplikacyjnych: pozwala uruchamiać systemy w maszynach wirtualnych, izolować zależności, szybciej odtwarzać środowiska testowe i bezpieczniej przenosić workloady między serwerami. W tym artykule pokazuję, gdzie takie podejście naprawdę daje przewagę, jak wygląda stos technologiczny od obliczeń po sieć i storage oraz kiedy lepiej postawić na prostszy model. Skupiam się na zastosowaniach praktycznych, bo właśnie tam ta platforma broni się najlepiej albo najszybciej ujawnia swoje ograniczenia.
Najważniejsze rzeczy, które warto wiedzieć o tej platformie
- Największy sens ma tam, gdzie wiele aplikacji działa na wspólnej infrastrukturze i potrzebuje izolacji, wysokiej dostępności oraz przewidywalnego kosztu.
- vSphere odpowiada za uruchamianie maszyn wirtualnych, vSAN za storage, a NSX za sieć i segmentację.
- VCF spina te warstwy w jeden model private cloud, a Workstation i Fusion pomagają w lokalnych testach i laboratoriach.
- Najczęstsze błędy to złe planowanie zasobów, długie życie snapshotów i brak testów odtwarzania po awarii.
- Najlepsze wyniki daje podejście etapowe: standaryzacja, automatyzacja, potem modernizacja aplikacji.
Do czego ta platforma sprawdza się najlepiej
Jeśli patrzę na zastosowania aplikacyjne, największą wartość daje tam, gdzie jedna maszyna fizyczna ma utrzymać wiele usług o różnych wymaganiach. Zamiast walczyć z pojedynczym serwerem, zespół dostaje możliwość izolowania obciążeń, szybkiego przywracania środowiska i przewidywalniejszego planowania zmian. To szczególnie ważne przy systemach biznesowych, które nie mogą sobie pozwolić na chaotyczne eksperymenty.
| Scenariusz | Dlaczego pasuje | Na co uważać |
|---|---|---|
| ERP, CRM i systemy finansowe | Izolacja, wysoka dostępność i łatwiejsze planowanie okien serwisowych. | Latencja storage i dobrze przetestowany backup aplikacyjny. |
| Testy, QA i środowiska deweloperskie | Szybkie klony, snapshoty i możliwość natychmiastowego resetu. | Rozrost zasobów i chaos w sieci testowej, jeśli nikt tego nie pilnuje. |
| Legacy applications | Uruchomienie starszego systemu bez przebudowy całego stosu. | Stary system operacyjny nie zwalnia z planu migracji i zabezpieczeń. |
| VDI i pulpity zdalne | Kontrolowany obraz systemu i centralne zarządzanie desktopami. | Nagłe skoki obciążenia na storage i sieci. |
| Aplikacje kontenerowe i hybrydowe | Jeden model operacyjny dla maszyn wirtualnych i kontenerów. | Większa złożoność i potrzeba automatyzacji od pierwszego dnia. |
| Oddziały i edge | Spójność wdrożeń w wielu lokalizacjach. | Trzeba dobrze zaplanować zdalne zarządzanie i odtwarzanie. |
W przypadku baz danych i systemów transakcyjnych najczęściej wygrywa dobrze dobrany storage, a nie dokładanie kolejnych vCPU. To właśnie dlatego wirtualizacja ma sens nie tylko jako oszczędność sprzętu, ale też jako sposób na uporządkowanie całego cyklu życia aplikacji. Kiedy już widać, do czego platforma jest najmocniejsza, łatwiej rozebrać ją na konkretne elementy techniczne.
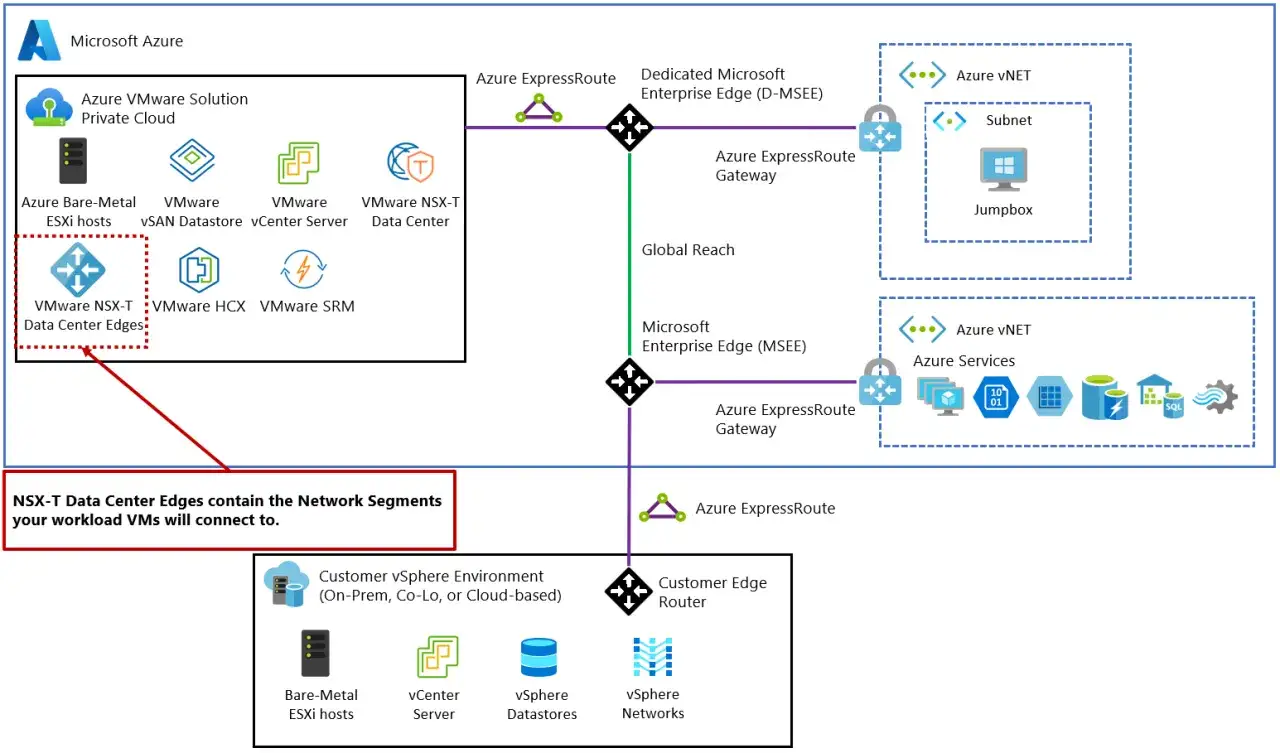
Jakie elementy platformy odpowiadają za aplikacje
W praktyce nie kupuje się jednego narzędzia, tylko zestaw warstw: compute, storage, networking, automatyzację i monitoring. Gdy te elementy są dobrze spięte, aplikacja dostaje przewidywalny grunt; gdy są rozdzielone i obsługiwane ręcznie, koszty operacyjne rosną szybciej niż sama infrastruktura.
| Element | Rola dla aplikacji | Kiedy używać |
|---|---|---|
| vSphere | Warstwa obliczeniowa, uruchamianie maszyn wirtualnych i centralne zarządzanie zasobami. | Gdy większość usług działa jako VM i potrzebujesz stabilnej podstawy pod produkcję. |
| vSAN | Software-defined storage z odpornością i skalowaniem razem z obliczeniami. | Gdy chcesz uprościć architekturę storage i uniknąć osobnej, ciężkiej macierzy. |
| NSX | Sieć, mikrosegmentacja i polityki bezpieczeństwa dla aplikacji. | Przy środowiskach wielowarstwowych, regulowanych i wielotenantowych. |
| VCF | Zintegrowany model private cloud, który spina całość w jeden sposób operowania. | Gdy chcesz jeden standard dla infrastruktury, operacji i zespołów aplikacyjnych. |
| VCF Automation i Operations | Self-service, monitoring i cykl życia środowisk. | Gdy zespoły aplikacyjne mają działać szybciej, ale bez utraty kontroli i zgodności. |
| Workstation i Fusion | Lokalne laboratoria, odtwarzanie błędów i testy na laptopie. | Przy development, QA i szkoleniach; dziś są dostępne bez opłat także dla użycia komercyjnego, edukacyjnego i prywatnego. |
| HCX | Migracja i mobilność aplikacji między lokalizacjami. | Gdy przenosisz workloady między data center, chmurą albo klastrami. |
Przy storage producent podaje możliwość redukcji TCO o 30% lub więcej, ale ja traktuję to jako sygnał, nie obietnicę. Taki efekt zależy od konsolidacji, polityki redundancji i tego, czy infrastruktura jest dobrze dopasowana do profilu aplikacji. W 2026 kierunek rozwoju jest jasny: mniej ręcznej obsługi hostów, więcej automatyzacji, API i jednego modelu dla maszyn wirtualnych, kontenerów oraz wybranych obciążeń AI. To prowadzi już wprost do pytania, kiedy taki model wygrywa z alternatywami.
Kiedy to rozwiązanie wygrywa, a kiedy lepiej szukać czegoś innego
Najczęstszy błąd to traktowanie wirtualizacji jak jedynej słusznej odpowiedzi. W praktyce czasem wygra public cloud, czasem bare metal, a czasem prosty lokalny hypervisor do testów; decyzja zależy od tego, jak długo ma żyć aplikacja, jak zmienny ma być ruch i kto ma utrzymywać całość.
| Kryterium | Platforma wirtualizacyjna | Public cloud | Bare metal |
|---|---|---|---|
| Koszt przy stałym obciążeniu | Zwykle korzystny przy wysokim wykorzystaniu i wielu aplikacjach. | Elastyczny start, ale koszt może rosnąć szybciej niż ruch. | Opłacalny przy jednej ciężkiej aplikacji i długim czasie życia. |
| Skalowanie | Dobre wewnątrz klastra i data center. | Najlepsze, jeśli ruch mocno faluje. | Najmniej elastyczne. |
| Kontrola i audyt | Wysoka, zwłaszcza w środowiskach regulowanych i z lokalizacją danych. | Wysoka, ale rozproszona po usługach i kontach. | Wysoka technicznie, lecz bez warstwy zarządzania. |
| Przenoszenie aplikacji | Zazwyczaj wygodne między hostami i lokalizacjami. | Zależy od użytych usług i integracji. | Najbardziej ograniczone. |
| Złożoność operacyjna | Średnia lub wysoka, ale dobrze porządkowana standardami. | Niższa na starcie, ale rośnie wraz z liczbą usług. | Niska warstwowo, lecz mniej elastyczna. |
Ja wybieram ten model wtedy, gdy aplikacje są krytyczne, żyją długo i trzeba nimi zarządzać w przewidywalny sposób. Jeśli projekt jest mały, jednorazowy albo mocno sezonowy, pełny stack potrafi być zwyczajnie zbyt ciężki. To właśnie dlatego przed wdrożeniem warto przejść przez konkretny proces, a nie zaczynać od liczenia hostów.
Jak wdrożyć aplikacje bez typowych błędów
Ja zaczynam od profilu aplikacji, nie od zakupu hostów. Najpierw chcę wiedzieć, ile procesora, pamięci i IOPS naprawdę potrzebuje system, jakie ma zależności i jaki akceptuje RPO oraz RTO. RPO mówi, ile danych można stracić, a RTO, jak szybko usługa ma wrócić po awarii. Bez tych dwóch liczb łatwo zbudować środowisko, które wygląda dobrze na papierze, ale nie dowozi w krytycznym momencie.
- Zbierz wymagania dla każdej aplikacji i oddziel środowiska dev, test oraz produkcyjne.
- Zdefiniuj standard obrazu maszyny wirtualnej, nazewnictwo i zasady aktualizacji.
- Dobierz storage i sieć do realnego profilu obciążenia, a nie do średniej z raportu.
- Włącz wysoką dostępność, sensowny balans zasobów i backup uwzględniający aplikację, nie tylko plik dysku.
- Zautomatyzuj provisioning, uprawnienia i cykl życia środowisk, żeby ograniczyć ręczną pracę.
- Przed go-live przetestuj odtworzenie, failover i migrację, a nie tylko sam start systemu.
Najczęstsze potknięcia
- Przydzielanie zbyt dużej liczby vCPU „na zapas”, co często pogarsza wydajność zamiast ją poprawiać.
- Trzymanie snapshotów przez tygodnie, choć miały służyć tylko do krótkiego okna zmian.
- Brak jasnego właściciela aplikacji i platformy, przez co nikt nie pilnuje standardów.
- Backup bez testu odtworzenia, czyli kopia, której nikt nigdy nie próbował przywrócić.
- Pomijanie ruchu sieciowego i storage, bo uwagę skupia się wyłącznie na CPU i RAM.
W materiałach producenta dla VCF Automation pojawia się przykład skrócenia czasu od zgłoszenia do gotowego środowiska o 49% oraz podobnej redukcji ręcznej pracy wokół cyklu życia aplikacji. To dobry sygnał, bo pokazuje, że automatyzacja nie jest ozdobą, tylko realnie skraca delivery i zmniejsza liczbę błędów. Kiedy środowisko już działa, największą różnicę zaczyna robić nie sam hypervisor, lecz dyscyplina operacyjna.
Jak utrzymać bezpieczeństwo i porządek po starcie
Po wdrożeniu największe znaczenie mają trzy rzeczy: sensowny backup, regularne patchowanie i monitoring, który patrzy na aplikację, a nie tylko na wskaźniki hosta. Tu zwykle wychodzi, czy zespół naprawdę zbudował platformę, czy tylko uruchomił kilka maszyn wirtualnych i liczy na szczęście. Bez tej dyscypliny nawet dobra architektura zaczyna z czasem puchnąć od wyjątków.
Backup i odtwarzanie
Snapshot to nie backup. Snapshot jest użyteczny przy krótkiej zmianie i szybkim rollbacku, ale nie zastępuje kopii zewnętrznej ani testu odtworzenia. Ja trzymam trzy warstwy: kopię maszyn, kopię danych aplikacji i osobny plan DR, czyli scenariusz odtworzenia całej usługi po awarii.
- Sprawdzaj, czy backup obejmuje także dane aplikacyjne, a nie tylko obraz systemu.
- Testuj odtworzenie w cyklu regularnym, najlepiej na osobnym środowisku.
- Traktuj archiwizację, backup i snapshot jako trzy różne narzędzia, a nie zamienniki.
Przeczytaj również: AirDrop - Szybkie pliki Apple - jak używać i unikać błędów
Monitoring i patchowanie
W monitoringu nie patrzę wyłącznie na CPU i RAM. Dla aplikacji często ważniejsze są latency storage, kolejki I/O, opóźnienia sieci, zajętość datastore i stan narzędzi w systemie gościa. To właśnie te metryki najczęściej pokazują problem zanim zobaczy go użytkownik.
- Planuj łatki hostów i systemów gości w jednym rytmie, żeby nie tworzyć niespójnych wersji.
- Mierz odchylenia od normy, a nie tylko twarde progi alarmowe.
- W środowiskach rozproszonych pilnuj spójnych polityk sieciowych i szybkiej ścieżki powrotu po awarii.
Jeśli aplikacja jest krytyczna, z mojego punktu widzenia warto okresowo sprawdzać też migrację między lokalizacjami, bo dopiero taki test pokazuje, czy cały model działa, a nie tylko jego pojedyncze elementy. Dzięki temu infrastruktura nie zostaje martwym kosztem, tylko realnym wsparciem dla zespołów aplikacyjnych.
Jak modernizować aplikacje bez wymiany całej infrastruktury naraz
Jeżeli miałbym sprowadzić temat do jednej decyzji, powiedziałbym tak: ta platforma najlepiej działa tam, gdzie aplikacje mają żyć długo, muszą być przewidywalne i dawać się zarządzać wspólnym modelem operacyjnym. W praktyce nie trzeba zaczynać od dużej rewolucji. Zwykle lepiej działa etapowanie: najpierw standard, potem automatyzacja, na końcu wybrane modernizacje.
- Najpierw porządkuję obecne aplikacje i usuwam chaos w środowiskach.
- Potem dokładam automatyzację, żeby skrócić provisioning i ograniczyć ręczne błędy.
- Dopiero później przenoszę wybrane usługi do modelu kontenerowego lub hybrydowego.
W 2026 najrozsądniejsze podejście to nie walka między chmurą publiczną, bare metal i wirtualizacją, tylko świadome użycie każdej warstwy tam, gdzie daje realną wartość. Jeśli patrzysz na VMware przez pryzmat aplikacji, widzisz nie sam hypervisor, lecz sposób na szybsze dostarczanie usług, prostsze utrzymanie i mniej niespodzianek przy wzroście skali.