
Atak DDoS potrafi unieruchomić stronę, panel administracyjny albo całe środowisko usługowe bez włamywania się do samej aplikacji. W praktyce chodzi o zalanie serwera ruchem, który z zewnątrz wygląda normalnie, ale w skali przekracza możliwości infrastruktury. W tym tekście wyjaśniam, jak taki atak działa, po czym go rozpoznać, jakie zabezpieczenia naprawdę mają sens i jak reagować, gdy dostępność zaczyna się sypać.
Najważniejsze rzeczy, które trzeba wiedzieć o tym ataku
- Celem jest dostępność, a nie zawsze kradzież danych. Usługa ma przestać odpowiadać albo działać dużo wolniej.
- Atak może uderzać w łącze, tabelę połączeń, DNS albo samą warstwę aplikacji, więc jedno zabezpieczenie rzadko wystarcza.
- Najbardziej podejrzane objawy to nagły skok ruchu, błędy 5xx, timeouty i nienaturalne wzorce w logach.
- Najlepiej działa połączenie kilku warstw obrony: CDN, WAF, rate limiting, filtrowanie sieciowe i plan reakcji.
- Samo dokładanie CPU i RAM zwykle tylko kupuje czas. Bez filtracji ruchu problem wraca.
- W środowiskach IT i automatyki przestój bywa szczególnie kosztowny, bo zatrzymuje monitoring, zdalny dostęp i obsługę alarmów.
Czym jest atak DDoS i dlaczego zatrzymuje usługę
Ja patrzę na to tak: to nie jest „dużo ruchu” w neutralnym sensie, tylko skoordynowane przeciążanie usługi z wielu źródeł. NIST ujmuje ten problem bardzo prosto, jako technikę ataku wykorzystującą wiele hostów jednocześnie. Skutek jest ten sam niezależnie od wariantu: serwer, load balancer, baza danych albo warstwa DNS przestają nadążać z obsługą legalnych użytkowników.
Najczęściej celem nie jest przełamanie kontroli nad systemem, tylko odebranie mu dostępności. To ważne rozróżnienie, bo firma może mieć poprawnie załatane systemy, a i tak zostać sparaliżowana przez zalew żądań. W praktyce cierpią nie tylko strony WWW, ale też API, panele HMI, bramki zdalnego dostępu, systemy monitoringu czy usługi używane w automatyce przemysłowej.
Jak podaje CISA, ataki tego typu mogą przeciążać infrastrukturę zarówno prostym zalewaniem ruchem, jak i bardziej precyzyjnymi żądaniami kierowanymi na konkretną warstwę. To prowadzi nas do drugiego ważnego pytania: jakie są rodzaje takich ataków i dlaczego nie reaguje się na nie tak samo.
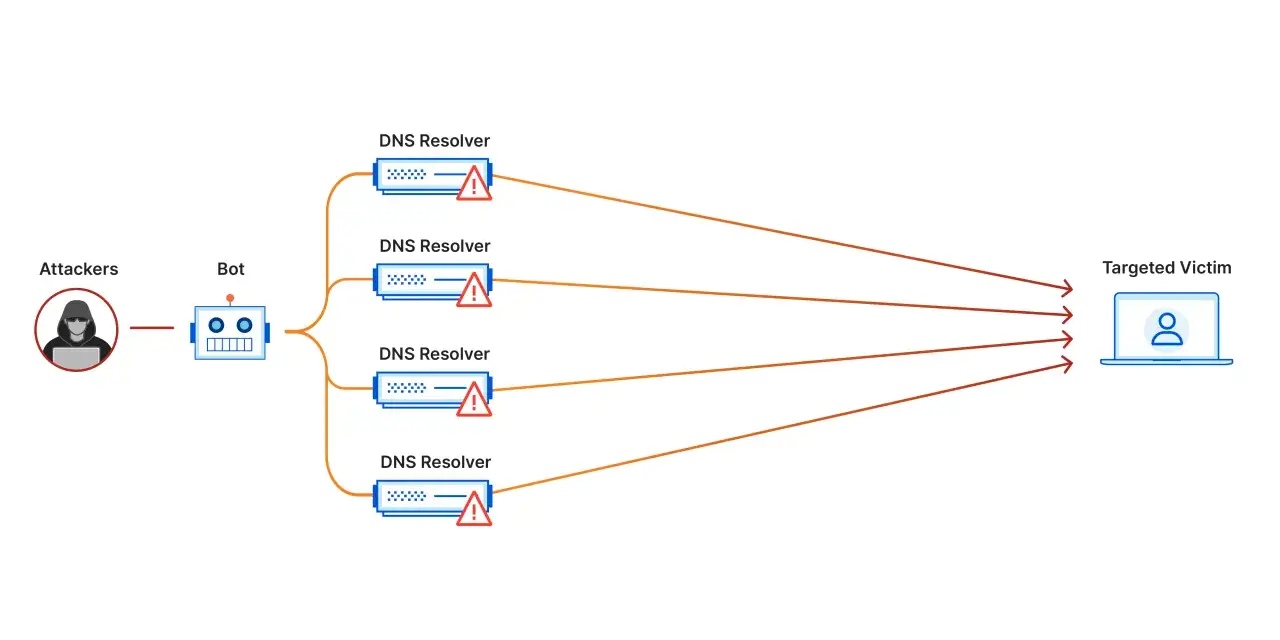
Jakie są najczęstsze warianty i czym się różnią
W praktyce nie traktuję DDoS jako jednego ataku, tylko jako rodzinę metod. Jedne próbują „zatkać rurę”, inne wyczerpują zasoby połączeń, a jeszcze inne uderzają w logikę aplikacji. Różnica ma znaczenie, bo od niej zależy, czy pomoże CDN, reguła WAF, filtracja na routerze, czy dopiero ochrona na brzegu sieci.
| Wariant | Co przeciąża | Typowy efekt | Co zwykle pomaga |
|---|---|---|---|
| Volumetric flood | Łącze i przepustowość | Strona staje się niedostępna lub bardzo wolna | Filtrowanie na brzegu, usługi ochrony ruchu, Anycast |
| SYN flood | Tabelę połączeń i zasoby TCP | Nowe sesje nie mogą się zestawić | Mechanizmy ograniczania połączeń, SYN cookies, filtry sieciowe |
| HTTP flood | Warstwę aplikacji i backend | API lub strona odpowiada, ale bardzo wolno albo tylko częściowo | WAF, rate limiting, cache, reguły behawioralne |
| Amplification / reflection | Ruch zwrotny z publicznych serwerów UDP, np. DNS | Ogromny napływ pakietów z wielu pozornie niezależnych źródeł | Blokowanie spoofingu, filtrowanie UDP, higiena DNS i routing |
Mechanizm amplifikacji jest szczególnie podstępny, bo napastnik potrafi wykorzystać publicznie dostępne serwery pośredniczące i sfałszowany adres źródłowy, żeby zwiększyć skalę zalewu. To dlatego w ochronie nie wystarczy patrzeć tylko na liczbę żądań. Trzeba rozumieć, co dokładnie jest obciążane i którędy ruch w ogóle wchodzi do infrastruktury.
Kiedy już rozpoznasz wariant, łatwiej ocenisz, czy problem wygląda jak atak, czy może jeszcze jak legalny skok popularności. Do tego przechodzę w następnej sekcji, bo w praktyce te dwa scenariusze bywają mylone.
Po czym rozpoznaję, że problem to coś więcej niż zwykły skok ruchu
Najbardziej oczywisty sygnał to spadek dostępności: strona nie ładuje się, API zwraca timeouty albo dashboardy odświeżają się z dużym opóźnieniem. Ale sam objaw nie wystarcza. Dla mnie ważniejszy jest wzorzec, czyli to, czy ruch zachowuje się nienaturalnie.
- Nagle rośnie liczba żądań lub transfer w logach, ale bez sensownego powodu biznesowego.
- Pojawiają się powtarzalne zapytania do tych samych endpointów, często z podobnymi nagłówkami albo user-agentami.
- Rosną błędy 5xx, timeouty i odrzucane połączenia na load balancerze.
- Logi pokazują źródła z wielu krajów albo z nietypowych sieci, których normalnie prawie nie widzisz.
- Warstwa aplikacji jest obciążona bardziej niż cache, a baza danych zaczyna odpowiadać wolniej mimo braku zmian po twojej stronie.
Nie każdy pik ruchu oznacza atak. Premiera produktu, kampania mailingowa, publikacja w mediach albo integracja partnerska też potrafią narobić hałasu. Różnica polega na tym, że legalny wzrost ruchu zwykle ma wyjaśnialny kontekst, a jego rozkład jest bardziej spójny z zachowaniem użytkowników. Atak natomiast często wygląda jak ruch „bez intencji użytkownika”, masowy i powtarzalny.
W praktyce odróżniam oba scenariusze po tym, czy wzorzec ma sens biznesowy, czy tylko statystycznie wygląda groźnie. Gdy to już widać, można przejść do rzeczy najważniejszej, czyli ograniczania skutków zanim usługa padnie całkowicie.
Jak ograniczyć skutki zanim dojdzie do przestoju
Najlepsza obrona to taka, która odcina problem jak najbliżej źródła. Jeśli atak dochodzi aż do origin servera, to znaczy, że infrastruktura jest zbyt „goła”. W praktyce stawiam na kilka warstw, bo każda z nich chroni przed innym typem przeciążenia.
| Mechanizm | Co robi | Dlaczego ma sens | Ograniczenie |
|---|---|---|---|
| CDN / reverse proxy | Pośredniczy w ruchu i buforuje treści statyczne | Ukrywa origin i zmniejsza liczbę zapytań do aplikacji | Nie zatrzyma wszystkiego, zwłaszcza ruchu dynamicznego |
| WAF | Filtruje żądania HTTP na warstwie aplikacji | Pomaga przy floodach na endpointy i formularze | Wymaga dobrych reguł i strojenia, inaczej robi false positive |
| Rate limiting | Ogranicza liczbę żądań z jednego źródła lub wzorca | Skuteczne przy nadużyciach na API i loginach | Nie wystarczy przeciwko rozproszonym źródłom |
| Anycast | Rozprasza ruch do wielu punktów sieciowych | Zmniejsza presję na pojedynczy węzeł | Wymaga odpowiedniej architektury po stronie dostawcy |
| uRPF i filtracja źródła | Weryfikuje, czy pakiet przychodzi z sensownego kierunku routingu | Pomaga ograniczać spoofing adresów IP | To element infrastruktury, a nie szybki „przycisk” dla aplikacji |
Ważna rzecz, którą widuję bardzo często: autoscaling nie jest ochroną przed atakiem. Może kupić czas, ale jeśli złośliwy ruch dalej przechodzi, to po prostu płacisz więcej za to samo przeciążenie. Dlatego skalowanie warto traktować jako element odporności, a nie jako jedyny mechanizm obronny.
W tym miejscu przydaje się też porządna higiena infrastruktury: ograniczenie publicznego dostępu do paneli administracyjnych, oddzielenie sieci produkcyjnej od stref zarządzania, ukrycie adresu origin i trzymanie ruchu serwisowego za VPN-em. Jeśli chcesz, żeby usługa była odporna, musisz zmniejszać powierzchnię ataku, a nie tylko dokładac zasoby. To prowadzi do pytania o ochronę na poziomie całej organizacji, nie tylko jednej aplikacji.
Jak zbudować ochronę na poziomie infrastruktury i aplikacji
Tu zaczyna się część, którą lubię najbardziej, bo zwykle daje największy zwrot z inwestycji. NIST rekomenduje między innymi RPKI, BGP origin validation, prefix filtering, source address validation oraz uRPF jako elementy szerzej rozumianej ochrony przed zakłóceniami i spoofingiem. Mówiąc prościej: jeśli sieć ma być odporna, routing i filtrowanie też muszą być uporządkowane.
W praktyce buduję ochronę warstwowo:
- Na brzegu sieci ustawiam usługę, która potrafi odsiać część ruchu zanim dotrze do serwera.
- Na warstwie aplikacji stosuję WAF i reguły dla konkretnych endpointów, zwłaszcza logowania, wyszukiwania i formularzy.
- Na poziomie DNS pilnuję redundancji, ograniczam publiczne rekordy i sprawdzam, czy strefy nie wystawiają więcej niż trzeba.
- Na poziomie serwera ograniczam backlog połączeń, ustawiam rozsądne timeouty i pilnuję sensownych limitów zasobów.
- W monitoringu trzymam baseline, czyli punkt odniesienia dla normalnego ruchu, żeby od razu widzieć nienaturalne odchylenia.
Warto też pamiętać o prywatności. Logi z ataku zawierają adresy IP, ścieżki URL, czasem identyfikatory sesji i parametry zapytań, więc trzeba traktować je jak dane wrażliwe operacyjnie. Nie udostępniałbym ich szerzej, niż to konieczne do analizy incydentu. To samo dotyczy informacji o topologii sieci, bo zbyt szeroko ujawniona architektura ułatwia kolejne próby sabotażu.
Jeżeli infrastruktura obsługuje środowisko automatyki, sprawa jest jeszcze poważniejsza: utrata dostępności panelu może odciąć podgląd alarmów, zdalne sterowanie i diagnostykę. Dlatego ochrona na poziomie firmy nie jest luksusem, tylko częścią ciągłości działania. Kiedy ten fundament jest gotowy, można sensownie przejść do tego, co robić w samym incydencie.
Co robić podczas incydentu i po jego zakończeniu
Gdy ruch zaczyna się sypać, najgorsze jest działanie bez kolejności. Ja zawsze zaczynam od potwierdzenia, że to rzeczywiście atak, a nie awaria dostawcy, błędna konfiguracja albo problem z backendem. Dopiero potem uruchamiam plan reakcji.
- Sprawdź monitoring, logi i alerty z kilku źródeł jednocześnie, a nie tylko z jednego dashboardu.
- Włącz lub podnieś poziom ochrony na brzegu sieci, WAF i reguły rate limiting dla najbardziej obciążonych endpointów.
- Jeśli to konieczne, przełącz frontend na tryb statyczny albo stronę serwisową, żeby chronić origin.
- Utrzymuj kontakt z dostawcą hostingu, CDN lub operatorem łącza, bo oni często widzą więcej niż twój własny monitoring.
- Zabezpiecz logi i inne ślady incydentu, zanim zaczniesz je porządkować lub rotować.
- Nie wyłączaj pochopnie zabezpieczeń tylko po to, żeby „zobaczyć, co się stanie”. To zwykle kończy się pogorszeniem sytuacji.
Po incydencie najważniejsza jest analiza przyczyny, nie samo odhaczenie awarii. Zadaję wtedy trzy pytania: co było celem ataku, którędy wszedł ruch i dlaczego obrona nie zatrzymała go wcześniej. Jeśli w tle był błąd konfiguracyjny, otwarty port, słaby limit żądań albo publiczny panel administracyjny, trzeba to poprawić od razu.
Nie zakładałbym też automatycznie, że każdy DDoS oznacza kompromitację danych. Sam atak nie musi oznaczać wycieku, ale może ujawnić słabe punkty infrastruktury, które później wykorzysta ktoś inny. Dlatego po zakończeniu incydentu warto jeszcze raz sprawdzić polityki dostępu, rotację sekretów, widoczność logów i zakres uprawnień zespołu.
Na czym skupić się najpierw, żeby nie przepalać budżetu
Jeśli miałbym wskazać tylko kilka działań, które zwykle dają największą poprawę, zacząłbym od tych punktów:
- Ukryj i odseparuj origin, żeby napastnik nie mógł od razu uderzyć w serwer źródłowy.
- Włącz ochronę na brzegu dla ruchu HTTP, DNS i UDP, bo tam najczęściej zaczyna się przeciążenie.
- Strojenie WAF i rate limiting oprzyj na realnym ruchu, nie na domysłach.
- Przygotuj runbook, czyli prostą instrukcję reakcji z kolejnością działań i kontaktami do dostawców.
- Testuj scenariusze awaryjne regularnie, bo dokument, którego nikt nie ćwiczył, w kryzysie działa słabo.
Największą różnicę robi nie pojedyncze narzędzie, tylko połączenie kilku warstw: filtrowania na brzegu, ograniczania żądań, obserwacji wzorców ruchu i gotowej procedury reakcji. W środowiskach IT i automatyki dostępność jest częścią bezpieczeństwa, więc traktuję ochronę przed takim atakiem jako element projektu, a nie dopisek po wdrożeniu. Jeśli ta baza jest dobrze zrobiona, nawet mocny incydent da się szybciej opanować i łatwiej z niego wyciągnąć wnioski.